# Perceptual Similarity
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric.
- Brief Introduction
- Main contributions
- Methodology
- Deep Feature Spaces
- Experiments
- Conclusions
- Referred in
🌏 Source
Downloadable at: Open Access - CVPR 2018. Source code is available at: GitHub - richzhang/PerceptualSimilarity.
# Brief Introduction
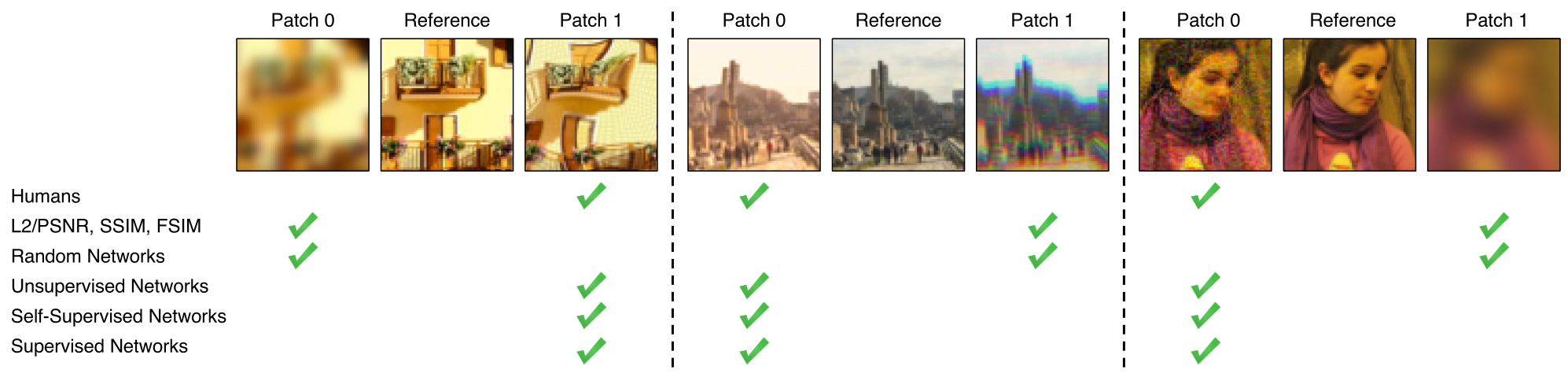
The paper argues that widely used image quality metrics like SSIM and PSNR mentioned in image-quality-assessment are simple and shallow functions that may fail to account for many nuances of human perception. The paper introduces a new dataset of human perceptual similarity judgments to systematically evaluate deep features across different architectures and tasks and compare them with classic metrics.
Findings of this paper suggests that perceptual similarity is an emergent property shared across deep visual representations.
# Main contributions
In this paper, the author provides a hypothesis that perceptual similarity is not a special function all of its own, but rather a consequence of visual representations tuned to be predictive about important structure in the world.
- To testify this theory, the paper introduces a large scale, highly varied perceptual similarity dataset containing 484k human judgments.
- The paper shows that deep features trained on supervised, self-supervised, and unsupervised objectives alike, model low-level perceptual similarity surprisingly well, outperforming previous, widely-used metrics.
- The paper also demonstrates that network architecture alone doesn't account for the performance: untrained networks achieve much lower performance.
The paper suggests that with this data, we can improve performance by calibrating feature responses from a pre-trained network.
# Methodology
# The perceptual similarity dataset
This content is less related to my interests. I'll cover them briefly.
- Traditional distortions: photometric distortions, random noise, blurring, spatial shifts, corruptions.
- CNN-based distortions: input corruptions (white noise, color removal, downsampling), generator networks, discriminators, loss/learning.
- Distorted image patches.
- Superresolution.
- Frame interpolation.
- Video deblurring.
- Colorization.
# Similarity measures
# Deep Feature Spaces
# Network activations to distance
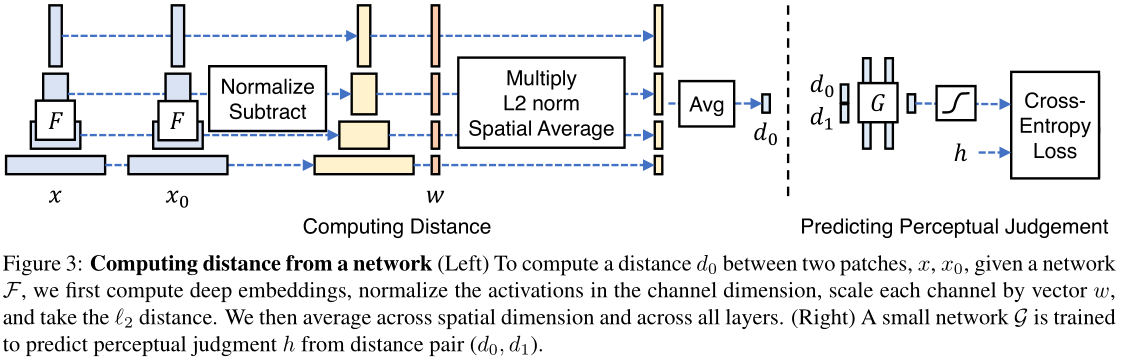
The distance between reference and distorted patches
# Training on this data
The paper considers the following variants:
- lin: the paper keep pre-trained network weights fixed and learn linear weights
- tune: the paper initializes from a pre-trained classification model and allow all the weights for network
- scratch: the paper initializes the network from random Gaussian weights and train it entirely on the author's judgments.
Finally, the paper refer to these as variants of the proposed Learned Perceptual Image Patch Similarity (LPIPS).
# Experiments
# Performance of low-level metrics and classification networks
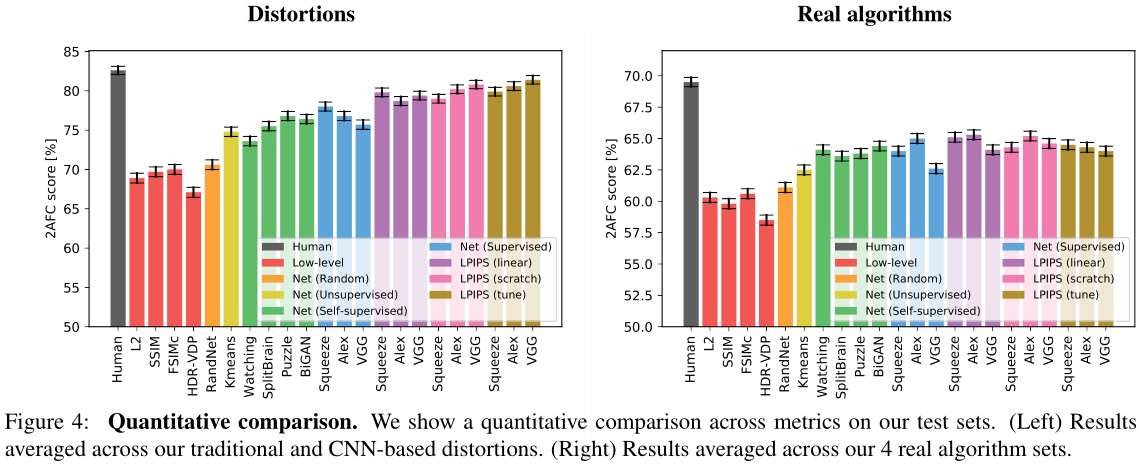
Figure 4 shows the performance of various low-level metrics (in red), deep networks, and human ceiling (in black).
# Metrics correlate across different perceptual tasks
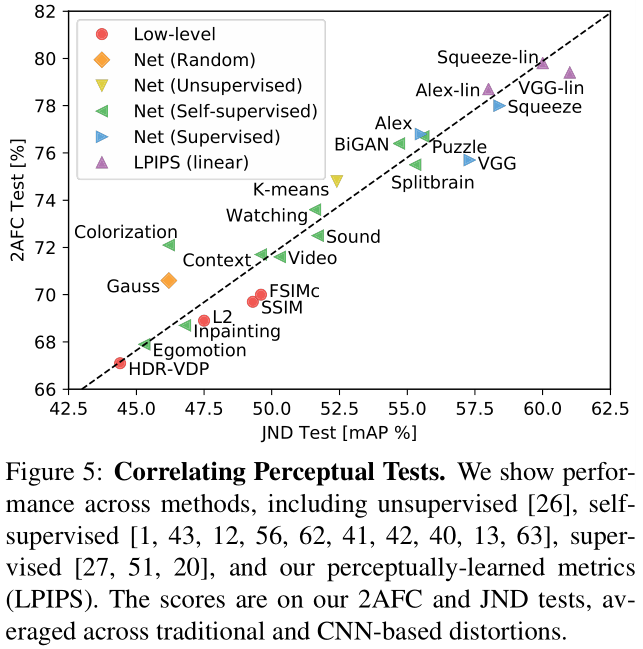
The 2AFC distortion preference test has high correlation to JND:
# Where do deep metrics and low-level metrics disagree?

Pairs which BiGAN perceives to be far but SSIM to be close generally contain some blur. BiGAN tends to perceive correlated noise patterns to be a smaller distortion than SSIM.
# Conclusions
The stronger a feature set is at classification and detection, the stronger it is as a model of perceptual similarity judgments.
Features that are good at semantic tasks, are also good at self-supervised and unsupervised tasks, and also provide good models of both human perceptual behavior and macaque neural activity.
# Referred in
- papers
- | Paper Title | Publication | Source Code | | perceptual-similarity | CVPR 2018 | richzhang/PerceptualSimilarity | | pieapp | CVPR 2018 | prashnani/PerceptualImageError |